Definição
Paralelizar atividades sequenciais, exemplo:
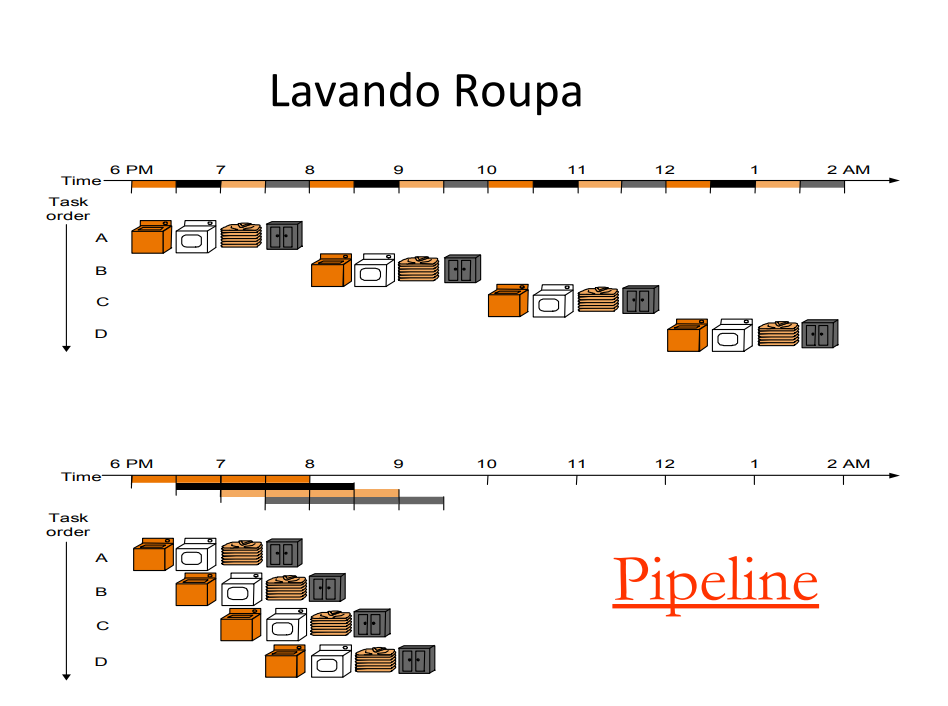
Uma etapa de lavagem recebe uma nova trouxa de roupas no momento em que fica ociosa, ao invés de esperar a mesma trouxa de roupas finalizar todas as suas etapas de lavagem. Enquanto a máquina de secar trabalha na trouxa A, a máquina de lavar (que finalizou a lavagem da trouxa A na etapa anterior), recebe a trouxa B, e assim sucessivamente. Todas as máquinas devem executar alguma tarefa, diminuindo ao máximo tempo de ociosidade.
- Ajuda no throughput (vazão, como num cano) da carga de trabalho
- Tarefas feitas simultaneamente
Pipeline clássico do MIPS
- Instruction Fetch (ifetch): busca instrução na memória
- Reg/Dec: decodificação e leitura do banco de registradores
- Exec: execução ou calcular endereço
- Mem: acessa memória de dados.
- WriteBack: escreve resultado no banco de registradores
Exemplo com 3 instruções do tipo load sendo executadas:
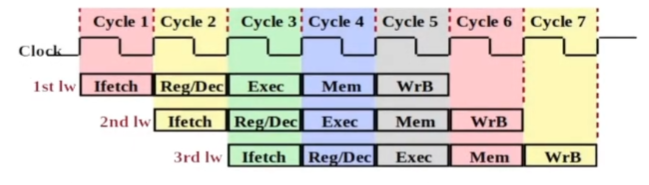
- A latência de uma única instrução continua sendo 5 ciclos
- throughput muito maior que sequencial
- tempo de ciclo é
~1/5do tempo de ciclo de uma implementação sem pipeline=
Hazards
- Situação onde uma instrução não pode executar alguma de suas etapas seguintes
- Ocorre devido a dependência entre instruções
- Quando um hazard não é resolvido, é inserido uma bolha no pipeline\
- Instrução que não faz nada, também chamada de stall
Hazards estruturais
- Hardware não consegue executar as combinações de instruções enviadas
- Ocorre devido a concorrência
- Imagine que as máquinas de lavar e secar se tornassem uma única máquina lava e seca
A principal solução é dividir o hardware em módulos menores que permitam execução simultânea. Dividir a lava e seca em duas máquinas, uma que lava e outra que seca.
Para decidir se isso vale a pena, deve ser considerado:
- Qual frequência esse hazard ocorre?
- Quanto custa dividir o hardware? Torna o projeto mais caro
- Mais de uma instrução causam o mesmo hazard no mesmo hardware?
Exemplo com cinco instruções load sendo executadas com apenas uma porta de leitura na memória:
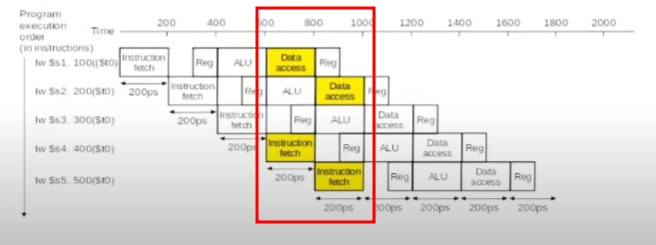
Ocorrência de hazard estrutural por leitura da memória em duas instruções diferentes. Um para ler o dado e outro para ler qual instrução deve ser executada. Solução:
- Inserir bolhas para adiamento da execução da instrução conflitante
- Duas portas de leitura, uma para instrução e outra para dados
Hazard de dados
- Ocorre quando uma instrução precisa de dados que devem vir de uma instrução anterior
- Imagine que uma meia lavada é encontrada sem seu par enquanto está sendo guardada, e seu par é encontrado ainda na máquina de lavar, é preciso que ela seja lavada, secada e passada antes de ter acesso.
Possíveis soluções: Encaminhar dados, fowarding, ao invés de esperar o dado no banco de registradores, encaminha-o diretamente para próxima instrução.
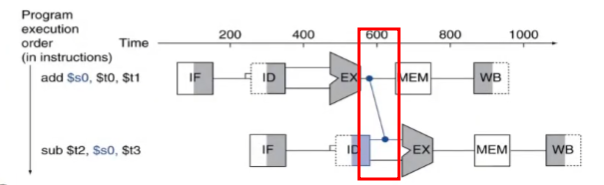
Reordenar código evitando bolhas, feito via compilador.
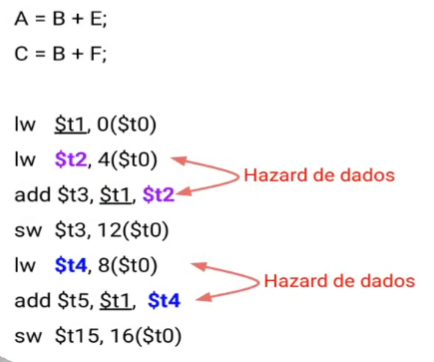
A leitura dos registradores, utilizando lw, está sendo feita logo antes das instrução de add, causando uma dependência e possível hazard. Para evitar, todas as instruções de lw podem ser feitas no início do código, através da reordenação.

Hazards de controle
- Ocorre quando as próximas etapas dependem do resultado de uma instrução anterior que está sendo executada via branch e jump. Acontece principalmente em condicionais como if.
- Para o exemplo da lavanderia, imagine que vamos limpar o uniforme de um time de futebol que está muito sujo e precisamos determinar o tipo de detergente ideal, temos algumas opções:
- Aguardar a primeira lavagem, para avaliar o resultado e modificar as configurações para lavar outra vez: stalls
- Podemos tentar prever a configuração baseado em critérios: previsão de desvio
- Previsão correta: a próxima instrução a ser executada é a que foi puxada pela previsão
- Previsão incorreta: adiciona bolhas para adiar a execução da instrução seguinte até carregar a correta
- Colocar outras roupas para lavar primeiro enquanto decidimos a configuração: delayed branch, como a reordenação de instruções do hazard de dados